Pure Storage Flasharray SQL Server Snapshot Torture...You Kinda Asked for This
By Argenis Fernandez
This post is archived here. Pleae reach out to me, Anthony Nocentino if you have any questions.
I gotta admit, some of you are really hard to convince. I’ve been saying for years that given a large enough database size (or a really small RTO storage based snapshots should be Plan A for recovering the database in the event of a disaster. Yes, you will have a Plan B, likely native backups. And Plan C. Maybe you’ll run out of letters because you’re so paranoid.
Here’s the thing though. You want to avoid the size-of-data operation that you will incur into by performing a byte-by-agonizing-byte restore. Snapshots will potentially save you hours and hours of twiddling your thumbs. Or biting your nails. They certainly help minimize the yelling from the bosses.
Fine. Let’s get this out of the way. Snapshots are not backups. They’re just amazing, amazingly fast restores.
Look, I’m not here to fight your religious war about how snapshots should not be called backups. I’m just gonna call them fast-as-fast restores(*) and be done with it. Because let’s be honest, with Pure Storage there’s absolutely nothing faster than a storage snapshot to recover a volume. Or volume(s). You get the idea. It’s about how fast you recover, every time.
Yes, I do understand that there are a million of considerations for something to be called a “backup”. We’ll get to those little by little – don’t expect a thorough post on that debate right now. Today I want to focus on one question: Are Pure Storage FlashArray snapshots stable, trustworthy enough that I can take them without pausing I/O against my database? Can I trust that the database will come online every time from a snapshot?
From my point of view the answer to that question is: If we’re talking about SQL Server, I’m confident that it will. If we’re talking about MongoDB, may the odds ever be in your favor. So really, it depends on the database engine and how it handles I/O. We’ll talk about MongoDB more in-depth some other day, though. It’s not that ugly of a story, it’s just not as straightforward as it is with SQL Server or for that matter every other RDBMS including Oracle, DB/2, MySQL, MariaDB, PostgreSQL, etc. It’s just that NoSQL engines are…special(**).
Let’s start with one fundamental fact: SQL Server is a relational database management system, and it relies on the Write-Ahead Logging (WAL) protocol to provide ACID properties. Everything SQL Server writes that’s expected to still be there upon a system crash gets written to a log before anything else can happen. This is where Pure’s FlashArray is extremely good at things. When we take a snapshot or we clone a volume, we include in that snapshot or clone every single I/O that’s been acknowledged back to Windows. By definition, completed writes against the transaction log cannot be cached by any volatile area of storage — for example, a DRAM cache on a SAN controller — otherwise they could be lost upon a system crash. That simply doesn’t happen with FlashArray. All writes are acknowledged once they hit one of our NVRAM modules and have been replicated to another NVRAM module attached to a different controller – and guess what NV stands for? Non-Volatile. Meaning, whatever we write to them is considered a persistent write.
So we have in FlashArray every I/O that has been acknowledged as completed. You tell FlashArray to take a snapshot or clone a volume, and Purity//FA takes care of the rest. We won’t go into the details of how Purity//FA handles snaps internally but I added that to the list of things to blog. I think I still owe people blog posts since 2016, though.
Now let’s go torture a FlashArray and see if its snapshots are as good as I claim they are.

The Setup
The setup is actually kind of simple: A single Windows Server 2019 VM running SQL Server 2019. A database that we’ll use as the “source” called FT_Demo. Same one you guys have seen @MarshaPierceDBA and I use in our demos for a long time now. It’s a bit under 2TB of actual allocated data. This time it resides on a 20TB volume as seen by Windows. The VM is running on top of vSphere 7.0 and the virtual disks are vVols.
We’re going to go ahead and create a workload against the source database, and while that is happening we will clone the volume on which the database resides 100 times on a loop without a sleep or pause instruction. We’ll then mount the 100 volumes to 100 different mount points in Windows, and we’ll attach the databases within those volumes to SQL Server. We will then not only check that the databases come online, but we’ll also run DBCC CHECKDB against them.

Let’s pause for a second and really think this through, though. I’m going to clone 2TB x 100 = 200TB worth of allocated data, and effectively will have added 20TB x 100 = 2 PETABYTES worth of virtual disks to the system. The power of data reducing storage arrays is amazing. I only added a couple of MB worth of metadata to the array once everything was said and done – that’s how much storage capacity I effectively consumed. Go ahead and try this in the cloud using EBS volumes or Azure Premium Storage, and then send me a copy of your bill (I won’t be covering it, no!). I promise you it will be a lot of fun to go over it.
Bring on the Pain!
On the VM I created 100 20TB volumes, 100 folders under an anchor drive for mount points, and then the real fun began.
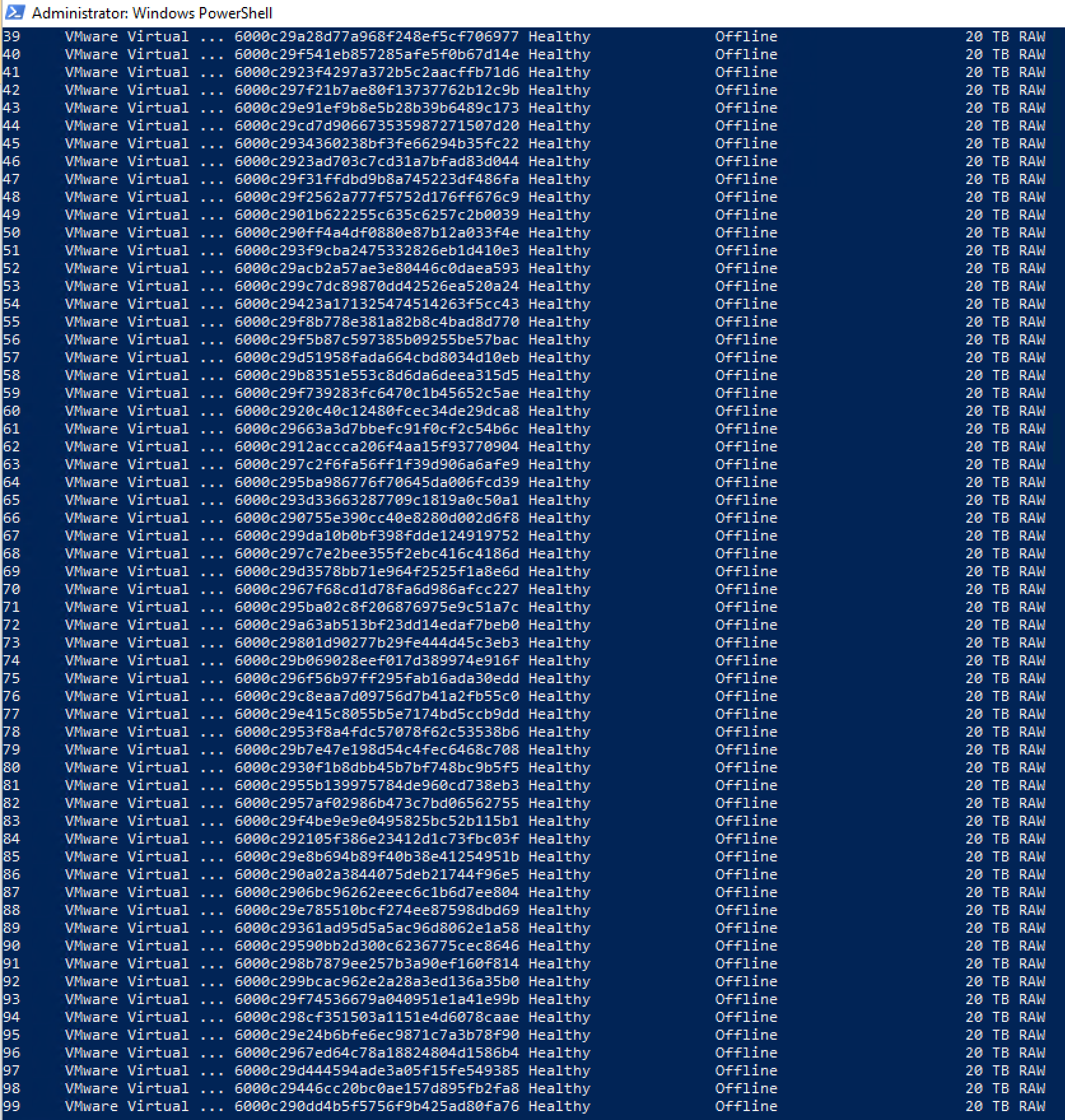
This is how things looked when I provisioned 100x 20TB volumes for the VM.
Once the volumes were there, I went ahead and kicked off some workload against the source database. Ready for crazy stuff? Let’s go.
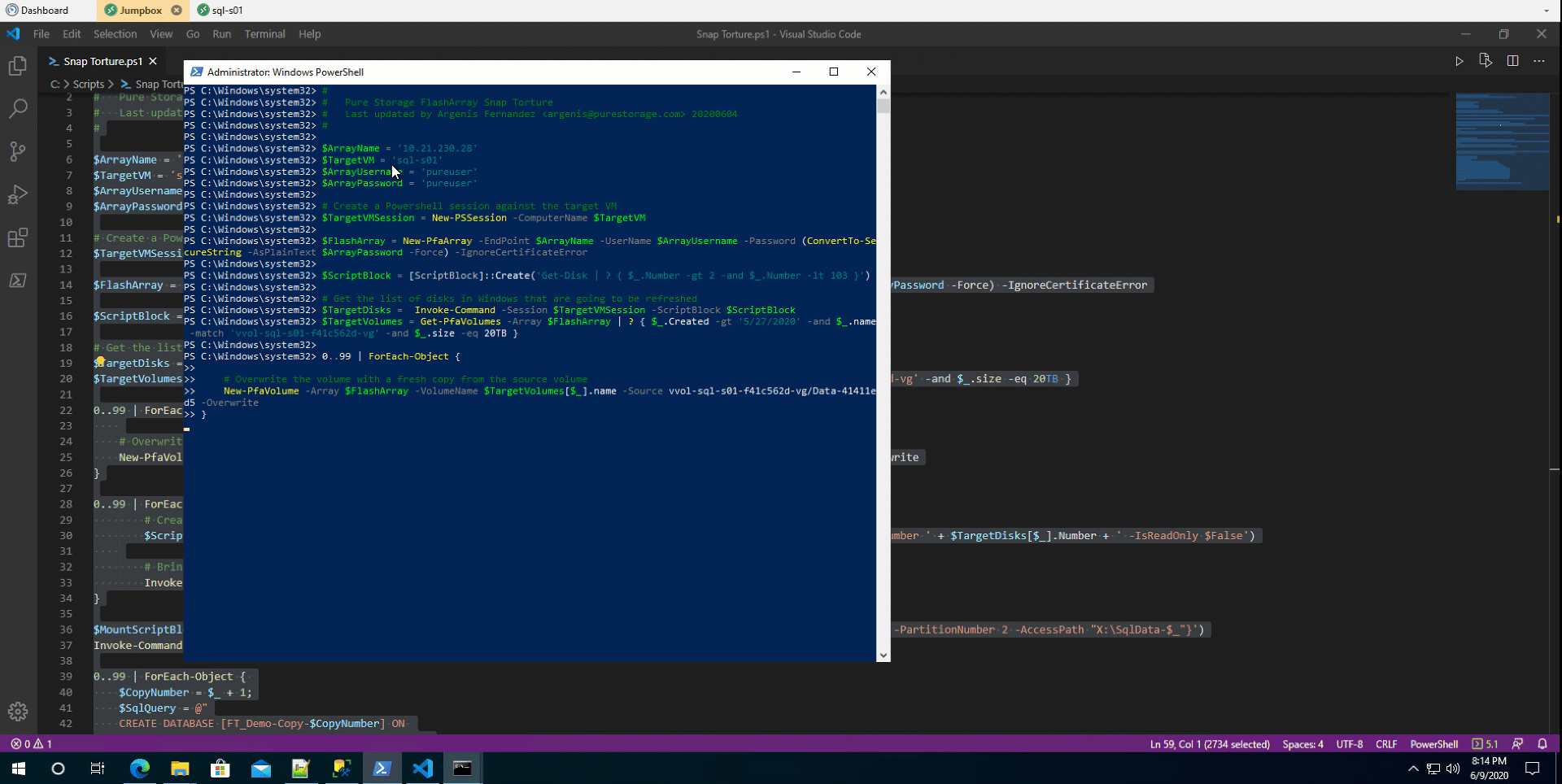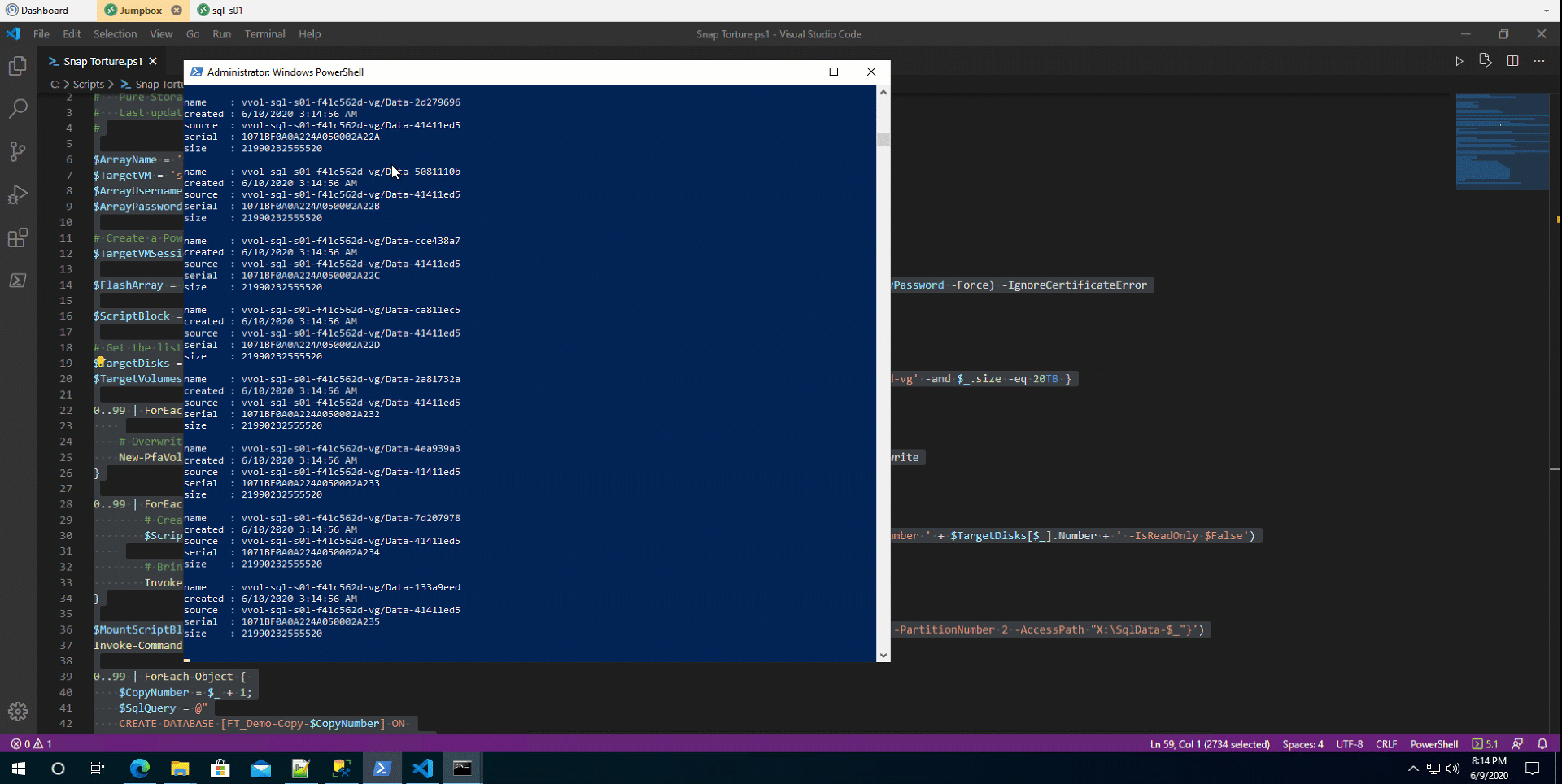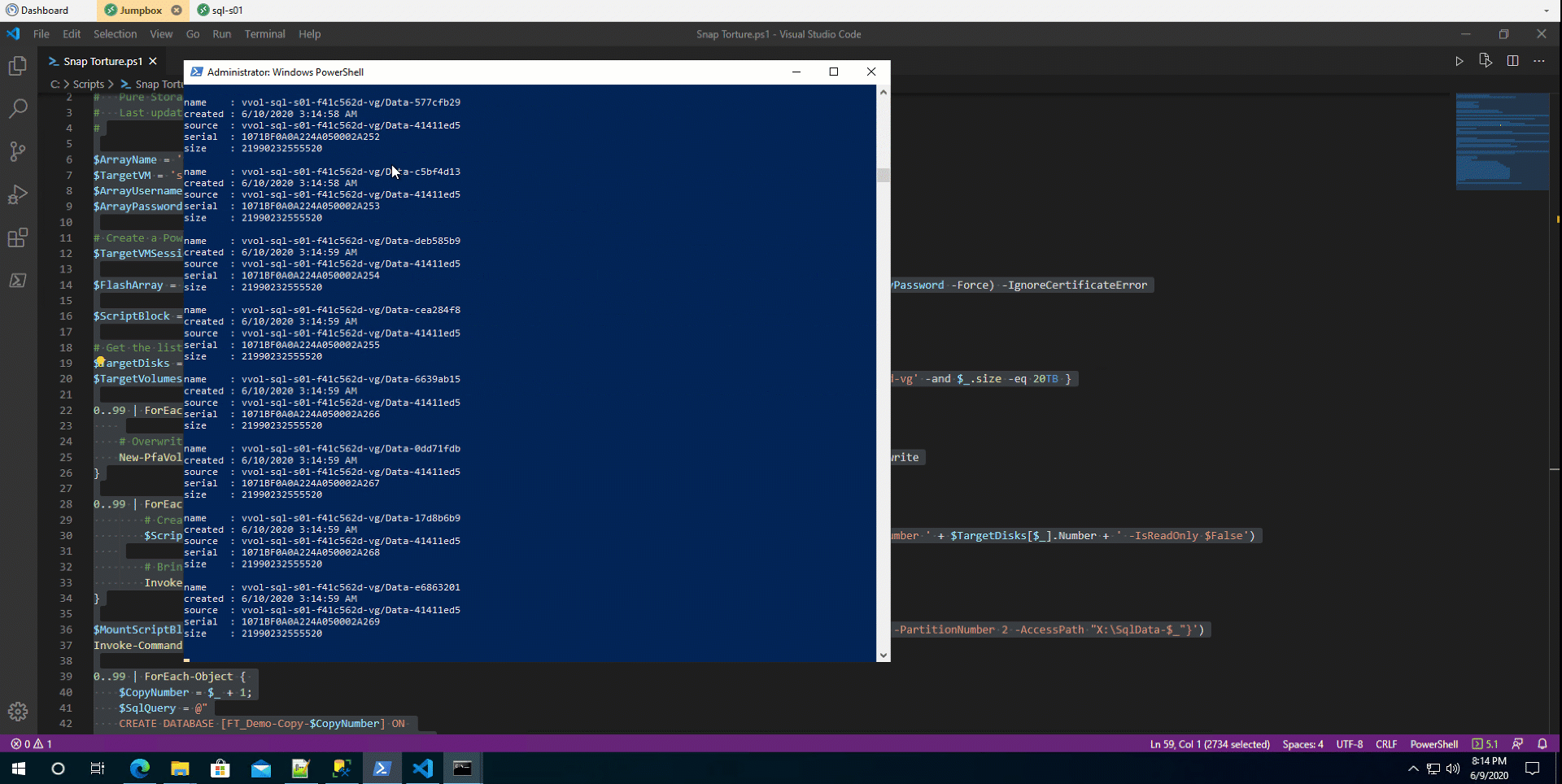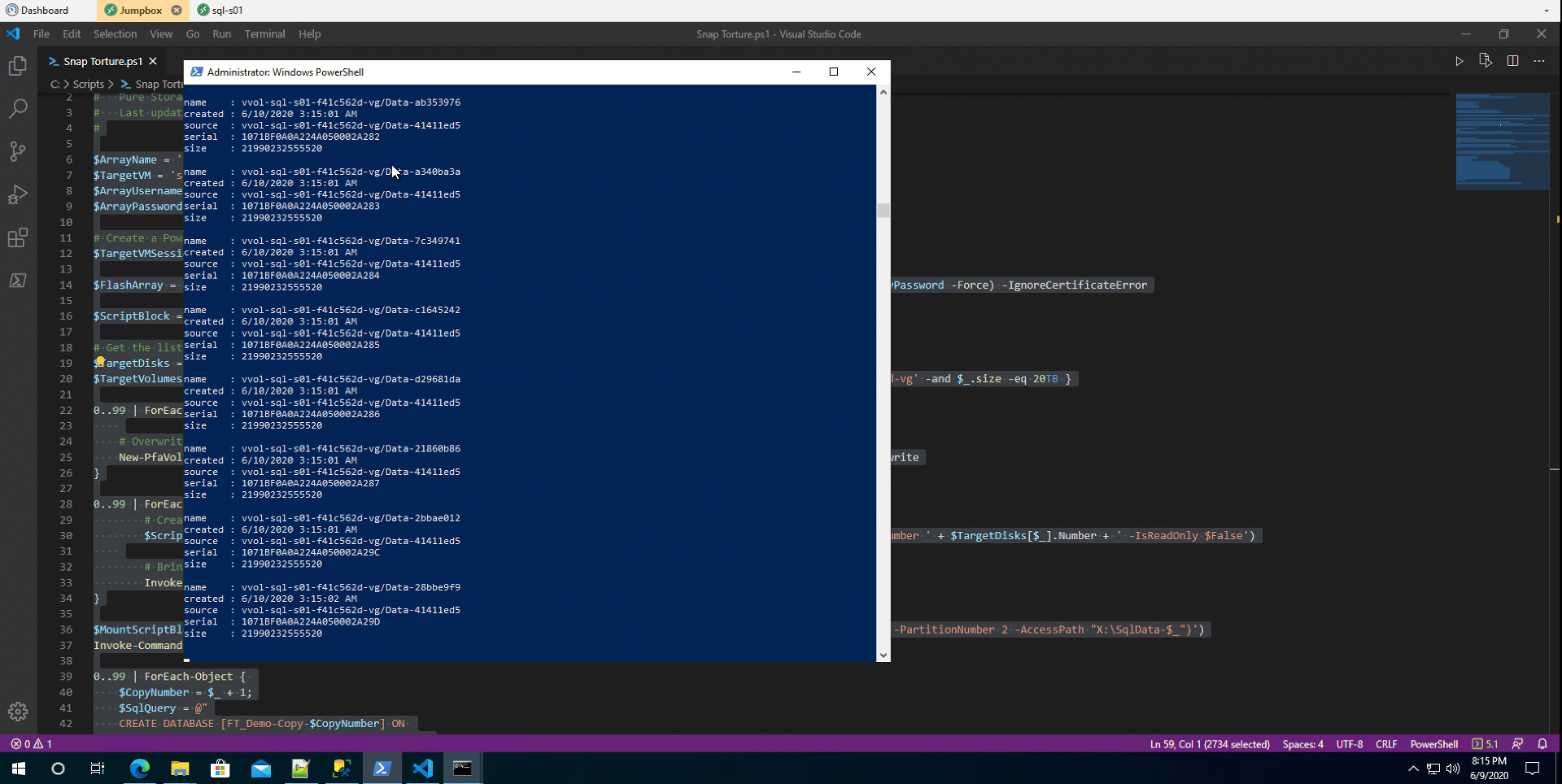
This is what it looked like when I was cloning the source database 100 times. So gratifying. Here’s the script I used. It’s horribly inefficient, I know. I never really spent time optimizing it. Just wanted to get something that worked.
Here’s the looooong video of me running the torture test. Warning: There are long periods of silence while stuff runs After all was done, I ran a query to gather row counts on the GuineaPig table across the 100 copy databases. You can see how the amount of records increase with every copy, as expected.
I started running CHECKDB on all the copy DBs. It’s gonna take a while…I’ll update the post once it finishes. I have 100 databases that came online just fine, though. And zero horror stories on my ERRORLOG. Happy to share it, just ask.
UPDATE: As I expected CHECKDB finished on all 100 copy databases with zero errors!. Happy to provide the ERRORLOGs to anyone interested. Here’s a screenshot of how the output looks like, after I gathered the output of sp_readerrorlog and pasted that in an Excel sheet:
Can you believe all of these copies only consume about 512GB of actual storage on the array?
So I need your feedback on what you just saw, please! Drop me a note on Twitter or comment below. There are obviously going to be more posts related to snapshots and how they work in Pure Storage FlashArray, as you can imagine. Tons of things to discuss. And definitely more on why this stuff is so important for recovery upon a disaster. For now, leave your comments, questions or concerns below!
Thanks for reading!
-A
UPDATE: I figured out why the VMs were slow in the lab when I recorded the video. One of my peers filled the array to over 100% capacity. Thanks, Remko 😁